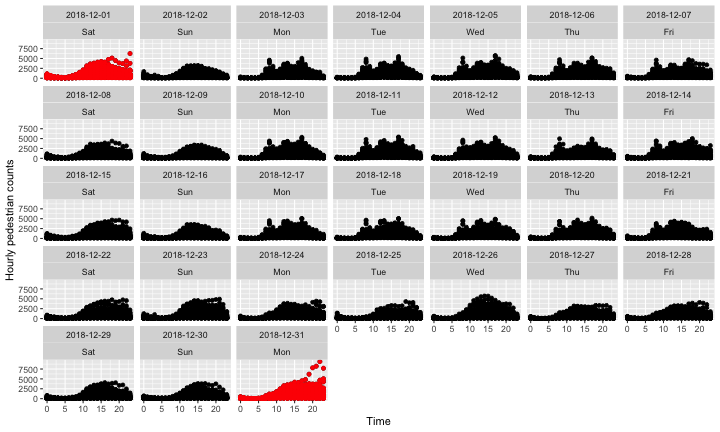
 Scatterplots of hourly pedestrian counts at 43 locations in the city Melbourne, Australia, from 1 December to 31 December 2018. Anomalous days detected by the stray algorithm using scagnostics are marked in red colour
Scatterplots of hourly pedestrian counts at 43 locations in the city Melbourne, Australia, from 1 December to 31 December 2018. Anomalous days detected by the stray algorithm using scagnostics are marked in red colour
Abstract
The HDoutliers algorithm is a powerful unsupervised algorithm for detecting anomalies in high-dimensional data, with a strong theoretical foundation. However, it suffers from some limitations that significantly hinder its performance level, under certain circumstances. In this article, we propose an algorithm that addresses these limitations. We define an anomaly as an observation that deviates markedly from the majority with a large distance gap. An approach based on extreme value theory is used for the anomalous threshold calculation. Using various synthetic and real datasets, we demonstrate the wide applicability and usefulness of our algorithm, which we call the stray algorithm. We also demonstrate how this algorithm can assist in detecting anomalies present in other data structures using feature engineering. We show the situations where the stray algorithm outperforms the HDoutliers algorithm both in accuracy and computational time. This framework is implemented in the open source R package stray
Supplementary notes can be added here, including code and math.
Priyanga Dilini Talagala
PhD in Statistics
My research interests include Computational Statistics, Anomaly Detection, Time Series Analysis and Machine Learning.